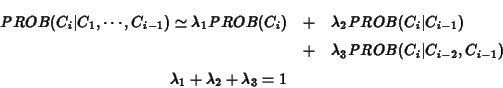

Next: 7.4 Obtaining Lexical Probabilities
Up: Chapter7Ambiguity Resoltion: Statistical Methods
Previous: �$B!{�(B Viterbi algorithm
- n-gram �$BE}7W$r$H$k>l9g�(B, �$B$$$C$?$$$I$l$/$i$$$N5,LO$N�(B corpus �$B$,$"$l$P�(B
�$B$$$$$N$+�(B? (categry �$B?t�(B 40)
- unigram
 401 = 40
401 = 40
- biigram
402 = 1600
- trigram
403 = 64,000
- four-gram
404 = 2,560,000
100�$BK|C18l$N�(B courps �$B$,$"$C$?$H$7$F$b�(B four-gram �$B$O$=$N$[$H$s$I$,�(B empty
trigram �$B$N>l9g$O$-$l$$$KJ,I[$7$F$$$k�(B category �$B$O�(B 15% �$B$[$I�(B
- smoothing
data sparseness �$B$NBP=hK!�(B
n-gram �$BE}7W$r�(B n-gram �$B$@$1$rMQ$$$k$N$G$O$J$/�(B, unigram, bigram
trigram.. �$B$NAH$_9g$o$;$GI=8=$9$k�(B
�$B$b$7�(B, trigram �$B$,�(B data sparseness �$B$N$?$a$K4Q;!$G$-$J$+$C$?>l9g�(B, bigram,
unigram �$B$G3NN(CM$,Jd40$5$l$k�(B,
best performance �$B$rF@$k$?$a$K�(B, 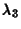 �$B$NCM$r;D$j$N�(B2�$B$D$h$jBg$-$/$9$k�(B
(trigram �$B$N3NN(CM$r;D$j$N�(B2�$B$D$h$jM%@h�(B)
�$B$NCM$r;D$j$N�(B2�$B$D$h$jBg$-$/$9$k�(B
(trigram �$B$N3NN(CM$r;D$j$N�(B2�$B$D$h$jM%@h�(B)
1999-08-03